


Our Natural Language Processing (NLP) research addresses basic research challenges and applied problems, partially in cooperation with industry partners.
Our main goal is to enable computers to understand and use natural language to support humans with numerous tasks, such as text classification, machine translation, question answering, sentiment analysis, text summarization, text generation, language modeling, dialog systems, and word sense disambiguation.
In the following video, Corinna presents one of our NLP projects. Read more…

OriginStamp is a web-based, trusted timestamping service that uses the decentralized Bitcoin blockchain to store anonymous, tamper-proof timestamps for any digital content. OriginStamp allows users to hash files, emails, or plain text, and subsequently, store the created hashes in the Bitcoin blockchain as well as retrieve and verify timestamps that have been committed to the blockchain. OriginStamp is free of charge and easy to use and thus allows anyone, e.g., students, researchers, authors, journalists, or artists, to prove that they were the originator of certain information at a given point in time. Read more…
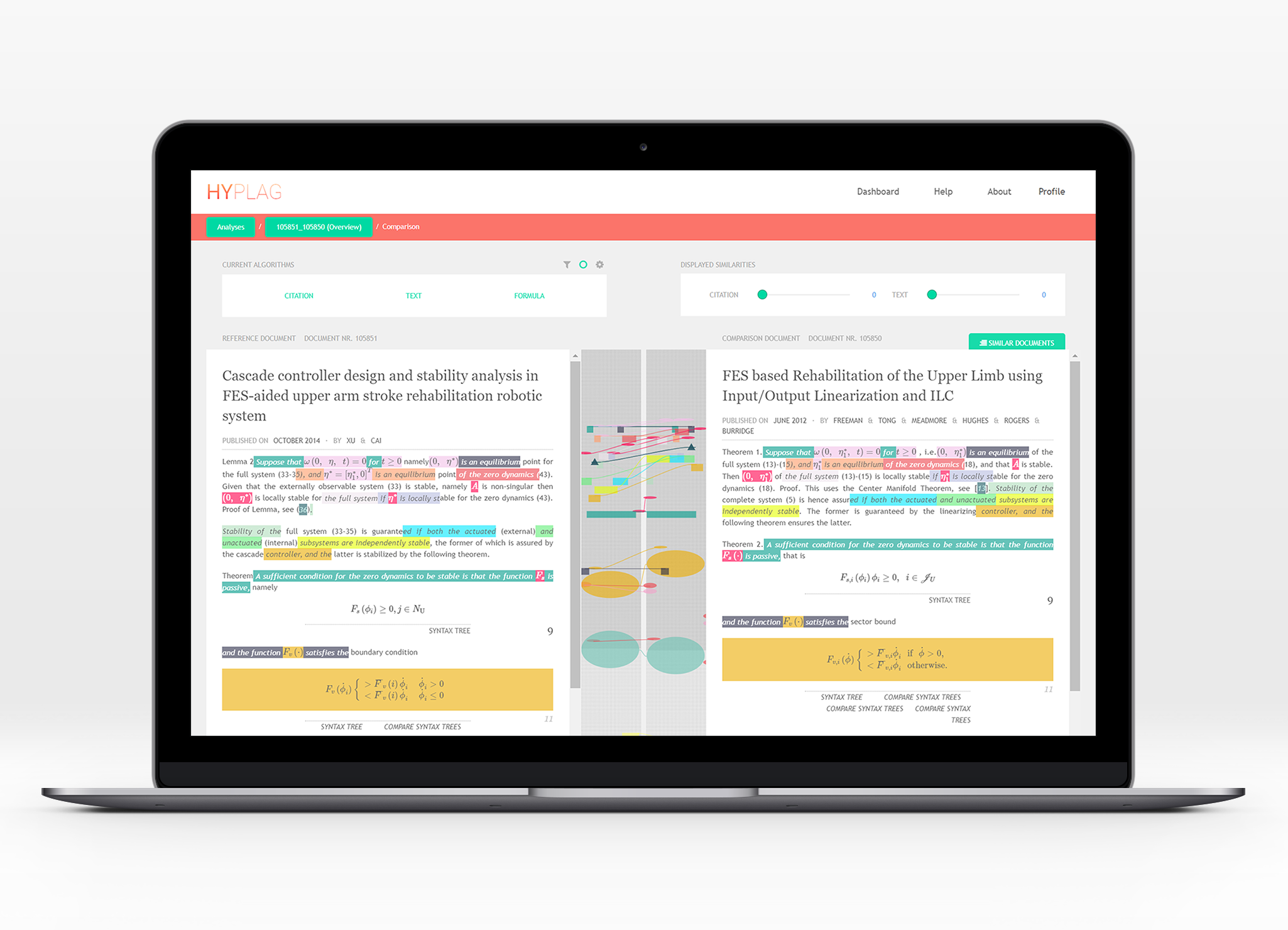
HyPlag is a system that implements hybrid plagiarism detection (hybridPD) – a novel approach capable of detecting also heavily disguised plagiarism in academic texts. The hybridPD approach combines the analysis of non-textual content in academic documents, such as citations, images, and mathematical expressions, with traditional text similarity analysis. Existing plagiarism detection software only examines text similarity, and thus typically fails to detect disguised plagiarism forms, including paraphrases, translations, or idea plagiarism. hybridPD addresses this shortcoming by additionally analyzing non-textual content to form a language-independent semantic “fingerprint” of document similarity.
The hybridPD approach implemented in HyPlag integrates and continues several of our previous research projects, particularly on Citation-based Plagiarism Detection (CbPD) and Mathematics-based Plagiarism Detection (MathPD).
Read more…
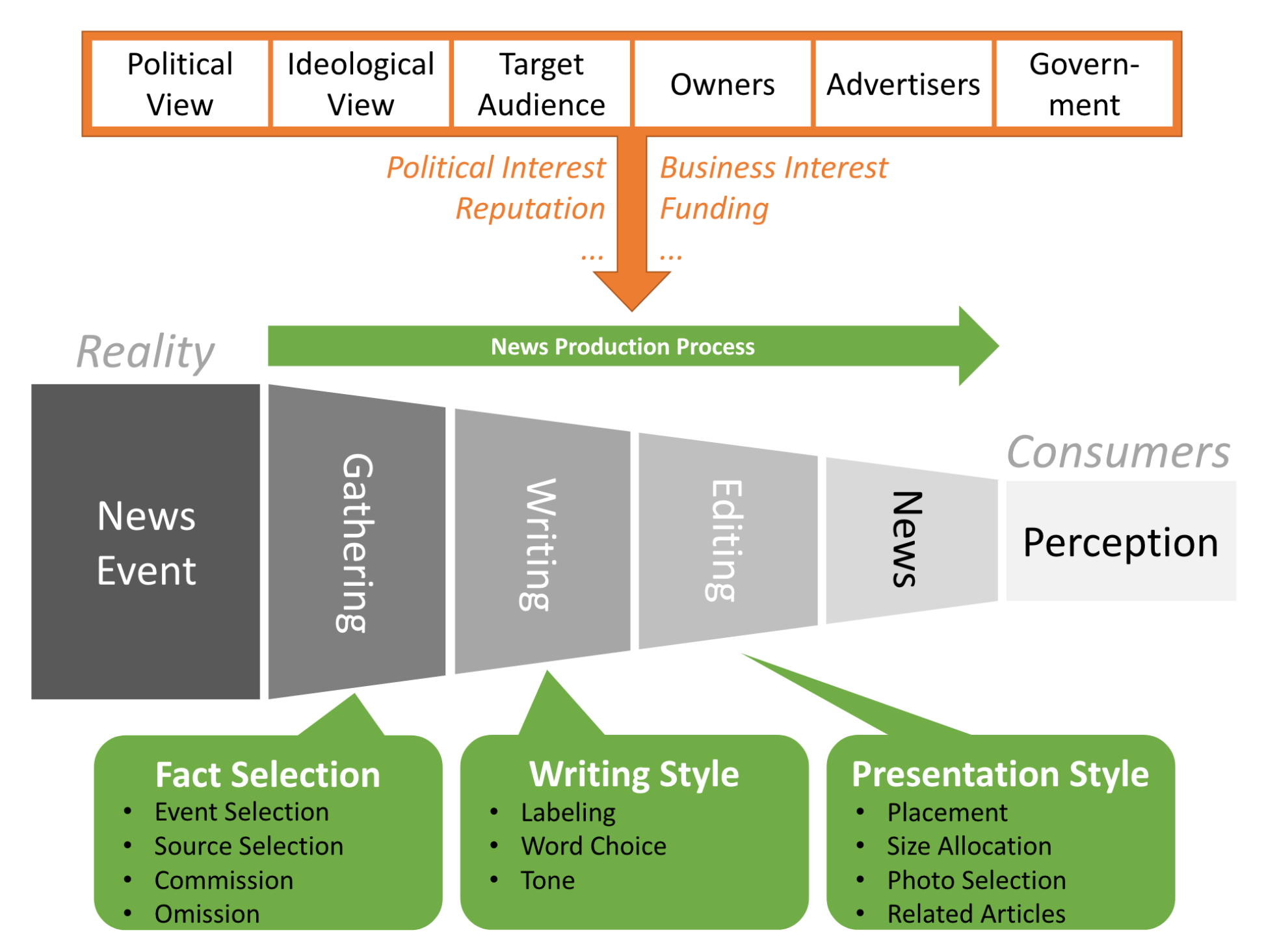
The following group of projects seeks to (semi-)automatically identify slanted news coverage, i.e., media bias, in news articles. Current projects include news-please (an integrated web crawler and information extractor for news articles), NewsBird (a news aggregator that reveals different perspectives in international news topics), and Giveme5W1H (a system that extracts phrases answering the journalistic 5W1H questions). Read more…

With an EXIST scholarship, we aim to provide fine-tuned classifiers that allow you to aggregate, analyze and understand text data in greater detail, while keeping an eye out for bias within both the models and the texts.

As part of the DFG-funded research project GI 1259/1-1: Methods and Tools to Advance the Retrieval of Mathematical Knowledge from Digital Libraries for Search-, Recommendation- and Assistance-Systems, we investigate fundamental methods and tools for making mathematical knowledge accessible to information retrieval tools. Read more…

The Decentralized Open Science Subgroup aims to employ decentralized information technology to foster the open science movement. As described in the twelve Vienna principles, Open Science aims to make scientific processes more transparent and results more accessible. Read more…

AI-based Decision Assistant for Process Plant Operations (ADAPPO or Plant Assistant in short) is an applied research project conducted as a collaboration between GippLab and eschbach GmbH funded by ZIM (Zentrales Innovationsprogramm Mittelstand) run by the German Ministry of Economic Affairs and Climate Action. Read more…
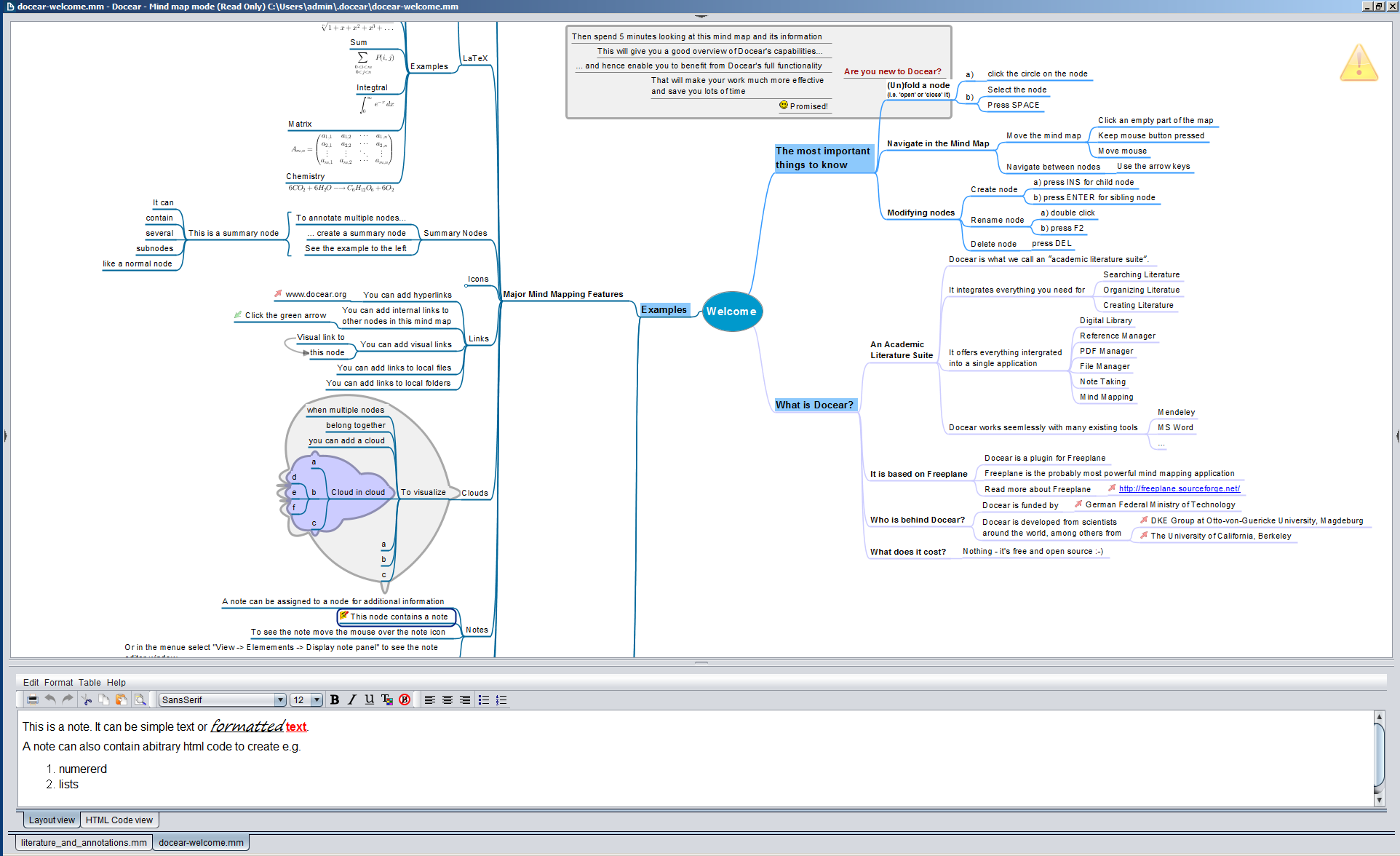
Docear combines a mind-mapping tool with a recommender system for academic literature and a reference manager. The mind maps allow users to organize their ideas and to import the annotations they made while reading PDFs, e.g., comments, highlights, or bookmarks. The software works with standard PDF annotations and thus can be used with different PDF viewers. Read more…

CitePlag is the first plagiarism detection system to implement Citation-based Plagiarism Detection (CbPD) – a novel approach capable of detecting heavily disguised plagiarism in academic texts.
Existing software only examines literal text similarity to detect plagiarism, and thus typically fails to detect disguised plagiarism forms, including paraphrases, translations, or idea plagiarism. CbPD addresses this shortcoming by additionally analyzing the citation placement in the full text of documents to form a language-independent semantic “fingerprint” of document similarity.
CitePlag implements several citation-based algorithms to analyze the citation patterns of publications.
Here, you can see a screenshot (click on the picture to try for yourself):
For more information, refer to this book or read more here…
Mr. DLib’s Recommendations as a Service (RaaS) allows operators of academic products to easily integrate a scientific recommender system into their products. The basic idea of Mr. DLib’s scientific recommender system is to calculate recommendations for research articles, call for papers, grants, etc. on Mr. DLib’s server. Operators of academic products may then request recommendations from Mr. DLib and display the recommendations to their users. Read more…
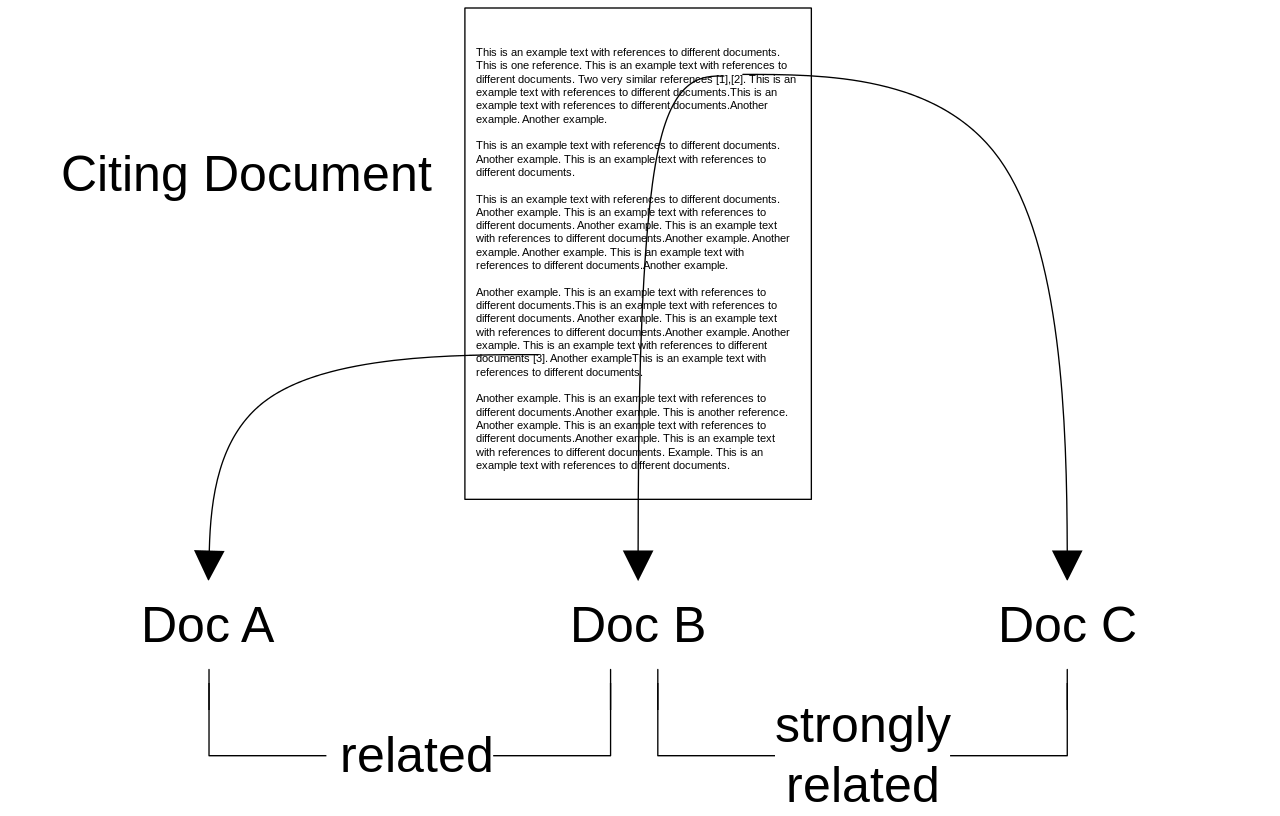
Co-Citation Proximity Analysis (CPA) is a method to compute both local and global instances of semantic similarity in academic documents by examining citation proximity in the full texts of documents. CPA was developed with two applications in mind: recommender systems and clustering. Regarding the first application, an improved measure of document semantic similarity, which computes similarity at a more fine-grained resolution, has the potential to significantly improve the relevance of academic literature recommendations. Read more…

CITREC is an open evaluation framework for citation-based and text-based similarity measures. It prepares the data of two formerly separate collections for a citation-based analysis and provides the tools necessary for performing evaluations of similarity measures. Read more…
AccessAngel is a software that enables your computer to lock itself automatically when you leave your workspace, ensuring that no unauthorized access is made to your data. The software achieves this by monitoring the Bluetooth connection between your cell phone and your computer. If the signal gets weak, e.g., when leaving the room, the computer locks itself automatically and unlocks itself upon returning. Read more…

In 2001, GPS receivers were slowly becoming smaller, and it seemed likely they would soon be integrated into mobile phones. At the time, they were still around the size of the mobile phone itself! However, in anticipation, we developed ‘Mobile GPS Locator’ – a software to geolocate mobile devices or PDAs from other mobile devices or from a desktop PC. The system allows pinpointing the location of your friends, co-workers, or any product running the software by simply using your cell phone. Use of the system only requires a cell phone with a compatible GPS receiver and support for Java’s J2ME (Java 2 Micro Edition). Infineon Technologies AG demonstrated the software at the 2002 CeBIT to give an outlook on the future of mobile developments. Read more…
“Every year approximately 7000 people die in car accidents in Germany. Studies estimate that 10% of these people could be saved if emergency services had been notified immediately. Bela Gipp had the idea to develop a system that automatically detects accidents, determines the location, and notifies the emergency services. Together with Jöran Beel and Lars Petersen, he developed a prototype capable of detecting automobile accidents by integrating a microcontroller and an acceleration sensor into a mobile phone. Sophisticated detection algorithms eliminate false alarms, for example, if the phone is dropped. In case of an accident, the emergency services are notified automatically. The location is determined using triangulation in the GSM network. In the future, the Global Positioning System (GPS) could be used to improve precision. Alternatively, if the car has airbags, their deployment could be used to trigger the emergency response. The presented system also features a software that displays the accident location on a map, and if enabled, the GSM-Guardian Angel transmits patient data, including blood group and allergies to medication.”
Text translated into English from the 1999, statement of the National Jury of ‘Jugend Forscht’ on the project “Der GSM-Schutzengel” (“The GSM-Guardian Angel”).In 2002, the project won 1st place in the state-level competition and 2nd place in the national-level competition, in which 7,800 participants competed.
We continued the research project after the Jugend Forscht competition, and sold the product in 2004. The idea has since been adopted, as eCall in Europe and as OnStar service in North America.
Read more…

Every second counts in avalanche search and rescue missions. In the past, avalanche dogs were called to the rescue. Today, in a time of mass tourism, avalanche rescue must make use of technology. Bela Gipp, Jan-Olaf Stiller, and Florian Krüger had the idea to develop just such an intelligent system. By using the images of an infrared camera mounted on a remotely controllable helicopter, the system can detect temperature differences between snow and human bodies. The helicopter then transmits this data and the images to a control system. For navigation, the helicopter uses a second true-color camera, a Global Positioning System (GPS), and an ultrasonic device for flying in poor visibility conditions. The system and all data collected while patrolling over the snow can be controlled and evaluated using a program over the Internet that the young inventors wrote themselves.
Text translated into English from the 1999, statement of the National Jury of ‘Jugend Forscht’ on the project “Der high-tech Bernhardiner” (“High-tech St. Bernard”). The project placed 1st at state level.Click here to see a list of all our DFG-funded projects.