

Mathematics-based Plagiarism Detection

Mathematics-based Plagiarism Detection (MathPD) is an approach to increase the detection effectiveness for disguised forms of academic plagiarism, such as paraphrases, translations and idea plagiarism, particularly for documents in the fields of Science, Technology, Engineering and Mathematics (STEM). STEM literature often interweaves symbolic language with natural language, e.g., by substituting parts of speech with mathematical expressions [4] and cites fewer sources [2]. Therefore, both word-based and citation-based plagiarism detection approaches (see our related research on Citation-based and Text-based Plagiarism Detection) often perform poorly for STEM literature.
The idea of MathPD is to complement other detection approaches by analyzing mathematical expressions to determine potentially suspicious similarity between documents. Mathematical expressions contain a high degree of semantic information, are language-independent, and hard to omit. Our goal is to combine the mathematics-based approach to plagiarism detection with citation-based and text-based detection approaches that we developed in previous research. Combined approaches that consider different feature types for similarity assessment are most promising to detect the wide range of academic plagiarism forms.
RESOURCES
We presented the first study on MathPD at the ACM Int. Conf. on Information and Knowledge Management (CIKM), 2017. Download: paper | poster.
Hereafter, we describethe data and resources for this preliminary investigation. Please refer to the paper for details on our detection approach and the methodology of our experiments.
Test cases
We collected research papers that had been retracted for plagiarism and that involved mathematical content. Four individuals with degrees in computer science (3), physics (1), and mathematics (1) reviewed 19 retracted papers and their sources in computer science (6 papers), mathematics (7 papers) and physics (4 papers). Additionally, we included one paper from bioengineering and one paper from medical engineering, for which the retraction notices described the plagiarized mathematics.
Most retracted papers contained significant amounts of math that were similar or identical to math in the source document and violated scientific principles. Several retracted papers also contained (near) copied text and/or figures. Most expressions in the retracted papers closely resembled the expressions in the source and were presented in similar order as well.
We selected 10 of the retracted papers we had reviewed manually as the query documents. The papers represent typical instances of similar mathematics we observed and are from disciplines covered by the NTCIR-11 MathIR Task dataset, which we use to create the reference collection.
Information about the ten selected test cases and the notes of the reviewers in different file formats are available from the HyPlag GitHub repository (user: hyplag-guest | pw: hybridPD). Due to license restrictions, we cannot share the fulltexts of the test cases, but include links to the publisher websites where they can be obtained.
Reference collection
To create the reference collection, we embedded the respective source documents of the ten query documents in the NTCIR-11 MathIR Task dataset [1]. The NTCIR dataset includes approx. 60 million formulae contained in 105,120 scientific papers from the fields computer science, mathematics, physics, and statistics retrieved from the arXiv preprint repository.
The NTCIR-11 MathIR Task dataset is freely available for research purposes, but requires accepting a license agreement.
Please refer to http://ntcir-math.nii.ac.jp/data/ for instructions on how to obtain the dataset.
Development Framework
Note that we have changed the math processing pipeline to integrate into HyPlag. For the latest version, lease refer to the
HyPlag GitHub repository (user: hyplag-guest | pw: hybridPD).
To implement our detection approach (see Section 3.2 of the paper), we extended the open source MathIR framework Mathosphere, which uses the distributed Apache Flink platform for data handling.
We added to Mathosphere a separate pipeline (see this part of the Mathosphere code) that accepts XHTML documents including MathML markup as input and provides descriptors of mathematical features as output. Developers can use the pipeline to easily access and compare the mathematics of an input document to the documents in a collection.
Data Conversion Tools
To convert the PDFs of the reviewed papers and their source documents to LaTeX, we used InftyReader [3].
Subsequently, we used the DaTeXML script to convert the LaTeX output of InftyReader to the XHTML format that includes MathML markup used for the NTCIR dataset. The script is a task-specific wrapper of the open source program LaTeXML. We did not split-up the converted documents into paragraphs as was done for the NTCIR dataset.
If you experience difficulties in reusing the test cases or our code, please contact us.
References
[1] A. Aizawa, M. Kohlhase, I. Ounis, and M. Schubotz. NTCIR-11 Math-2 Task Overview. In Proceedings of the 11th NTCIR Conference on Evaluation of Information Access Technologies, pages 88–98. National Institute of Informatics (NII), 2014.
[2] H. Moed, W. Burger, J. Frankfort, and A. Van Raan. The application of bibliometric indicators: Important field- and time-dependent factors to be considered. 8 (3-4): 177–203, 1985. ISSN 0138-9130. doi: 10.1007/BF02016935.
[3] M. Suzuki, T. Kanahori, N. Ohtake, and K. Yamaguchi. An Integrated OCR Software for Mathematical Documents and Its Output with Accessibility, pages 648–655. 2004. ISBN 978-3-540-27817-7. doi: 10.1007/978-3-540-27817-7_97.
[4] M. Wolska. A Language Engineering Architecture for Processing Informal Mathematical Discourse. In Towards Digital Mathematics Library, pages 131–136. Masaryk University, 2008.
RELATED PUBLICATIONS
- HyPlag: A Hybrid Approach to Academic Plagiarism Detection,
N Meuschke, V Stange, M Schubotz, B Gipp,
Proc. Int. ACM SIGIR Conf, on Research & Development in Information Retrieval, 2018.
(PDF | DOI | BibTex) - Analyzing Mathematical Content to Detect Academic Plagiarism,
N Meuschke, M Schubotz, F Hamborg, T Skopal, B Gipp,
Proc. ACM Conf. on Information and Knowledge Management (CIKM), 2017.
(PDF | Poster | BibTex)
MEDIA COVERAGE

Funding approved for 3-year research project by the DFG (German Research Foundation)
We are happy to announce that the DFG (German Research [...]
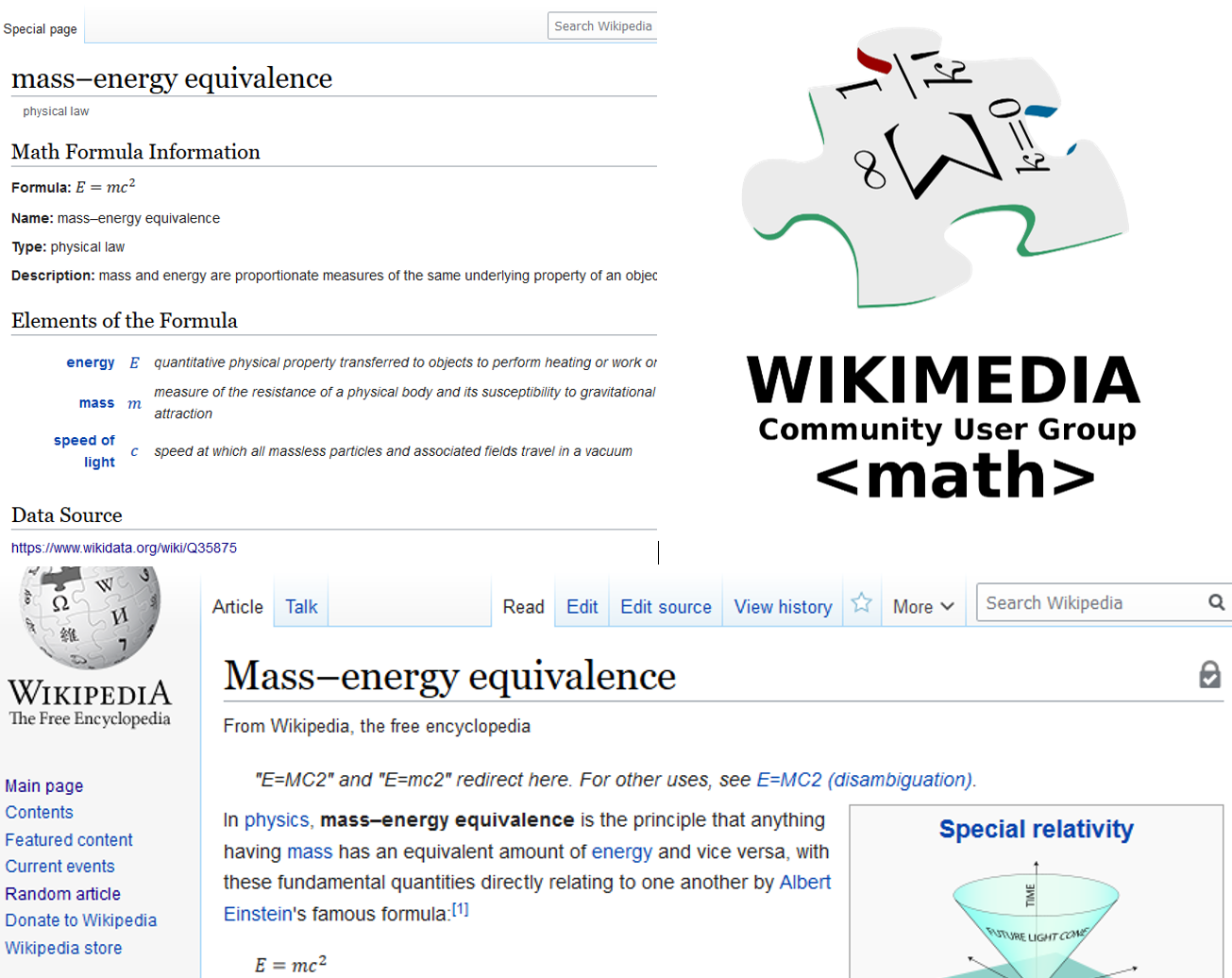
Wikipedia rolls out our research on providing semantic information for mathematical formulae
As of January 9, Wikipedia allows semantically enhancing mathematical formulae [...]
New DFG Project about math retrieval
The DFG, Germany’s organization for research funding, has awarded our [...]
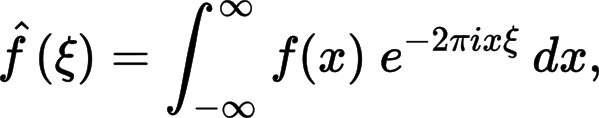
Improved math rendering in Wikipedia
Wikipedia is using a new approach for rendering mathematical formulae [...]
{kind=link}
CitePlag on public radio
The national public radio broadcasters Deutschlandfunk and Deutschlandradio Kultur covered our collaborative research on [...]